
꾸준하고 즐겁게
Classification의 문제에서 Compile에 쓰이는 Loss function의 사용 본문
728x90
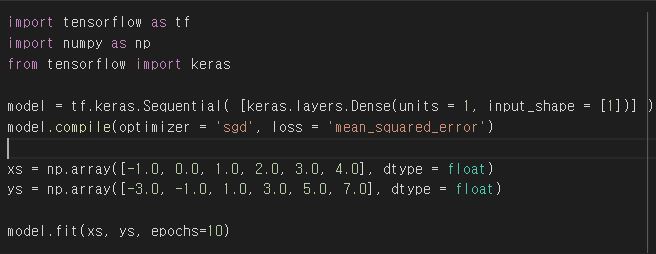
loss 함수는, 예측한 값과 실제 값을 비교해 얼마나 맞고 틀렸는지의 차이를 수치로 나타내주는 역할을 한다.
keras 모델의 Classification에서는 loss function들을 모델링의 문제에 적합한 것으로 골라 사용해야한다.
- binary_crossentropy : 0 또는 1과 같이 2개의 클래스로 분류하는 문제에서 쓴다. 결과값이 하나로 나온다.
- sparse_categorical_crossentropy : 3개 이상의 클래스를 정수로 분류하는 문제에서 쓴다. 역시 결과값이 하나로 나온다.
- categorical_crossentropy : 3개 이상의 클래스로 분류하는 문제에서 쓰는데, 결과값이 One Hot Encoding의 형태로 여러 개로 나온다.
※ 코드를 복사하려면 더보기를 누르세요.
더보기
import tensorflow as tf
import numpy as np
from tensorflow import keras
model = tf.keras.Sequential( [keras.layers.Dense(units = 1, input_shape = [1])] )
model.compile(optimizer = 'sgd', loss = 'mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype = float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype = float)
model.fit(xs, ys, epochs=10)
model.predict( [10.0] )
728x90
'Machine Learning' 카테고리의 다른 글
| Transfer Learning (0) | 2021.05.03 |
|---|---|
| Keras의 ImageDataGenerator 클래스 (0) | 2021.05.03 |
| Keras의 ModelCheckpoint (0) | 2021.04.30 |
| Keras 라이브러리를 활용해 작성한 사용자 정의 Callback 함수 (0) | 2021.04.30 |
| Learning Curve를 통해 Overfitting 확인하기 (0) | 2021.04.30 |
'Machine Learning' Related Articles
more



